




Table of contents
System design refers to the process of conceptualizing and structuring a software system to address specific requirements. It involves identifying the system's components, their relationships, and interactions, and designing their interfaces. System design encompasses architectural decisions, data flow, communication protocols, algorithms, and storage considerations. The goal is to create a robust, scalable, and efficient system that meets functional and non-functional requirements such as performance, reliability, and security. It requires knowledge of software engineering principles, design patterns, and trade-offs. System design is crucial in building complex software applications that effectively solve real-world problems.
At the core of system design is the identification and understanding of the problem domain. This involves analyzing user requirements, constraints, and objectives. Once the requirements are clear, system designers work on defining the system's structure and behavior.
Architectural decisions play a vital role in system design. Designers select appropriate architectural patterns and styles that determine how the components will interact and communicate. They consider factors like modularity, scalability, performance, and extensibility.
The design process includes defining data flow, storage mechanisms, and communication protocols. Designers choose suitable algorithms, data structures, and database models to optimize system performance and ensure proper data management.
During system design, non-functional requirements are also addressed. These include reliability, availability, security, and usability. Designers incorporate mechanisms for fault tolerance, data backup, access control, and user interface design to enhance the overall system quality.
System design is an iterative process that involves constant refinement and improvement. It requires collaboration among different stakeholders, such as software architects, developers, and project managers. Documentation, diagrams, and models, such as UML (Unified Modeling Language), are often used to visualize and communicate the system design.
Understanding Web/Mobile App Route
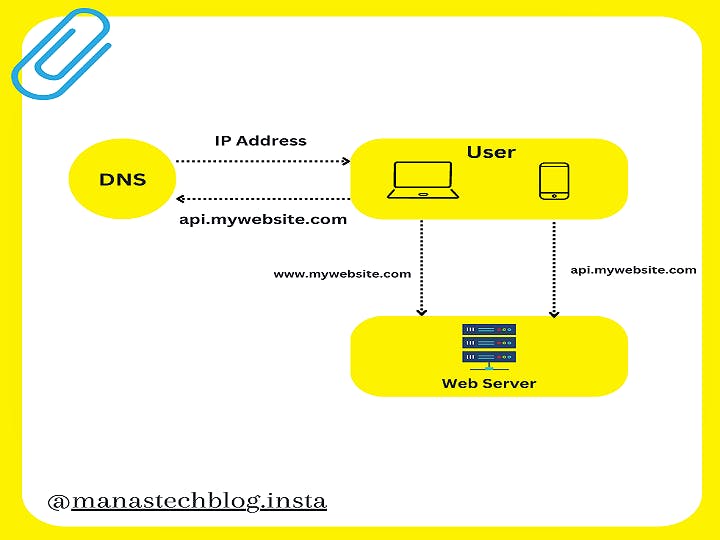
The Above figure shows the server setup where web application, database and other required services are running on a single server.
To understand the above layout, we require an understanding of the request flow and traffic source.
let's break it down into a series of steps:
Client Request: The user initiates an action on the web or mobile app, such as clicking a link or submitting a form. This sends a request from the client (browser or app) to the server.
DNS Resolution: The domain name of the server, such as mywebsite.com, needs to be resolved to an IP address. The client sends a Domain Name System (DNS) lookup request to a DNS server to obtain the IP address of the server.
Routing: Once the client has the IP address, it establishes a network connection with the server. The request typically goes through multiple network routers, which direct the traffic towards the server's network.
Application Server: The request reaches the application server, which hosts the web or mobile app logic. The server processes the request, interacts with databases or other external services, and generates a response.
Response Transmission: The server sends the response back to the client over the network. The response may include HTML, CSS, JavaScript, or other resources required to render the app's user interface.
Client Rendering: The client (browser or app) receives the response and renders the content based on the received data. The client interprets HTML, applies CSS styles, executes JavaScript code, and displays the app's interface to the user.
Throughout this process, various protocols such as HTTP(S) are used for communication between the client and server. The route from the server to the client involves several layers of networking, infrastructure, security, and application logic, working together to deliver a seamless user experience.
Below is a sample JSON response
JSON (JavaScript Object Notation) is a lightweight data-interchange format that is easy to read and write for humans, and also easy to parse and generate for machines. It is commonly used for transferring data between a server and a client in web or mobile applications, as it provides a structured and standardized format for data exchange.
{
"status": "success",
"data": {
"id": 12345,
"name": "John Doe",
"email": "johndoe@example.com"
}
}
Database Servers
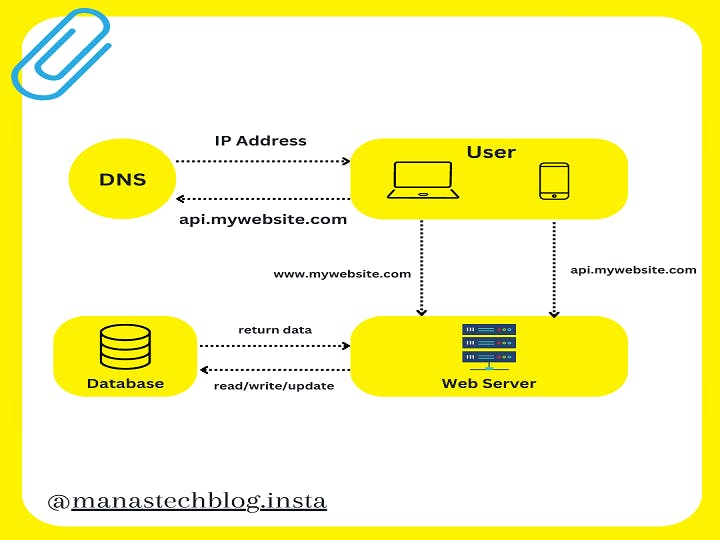
The Above figure shows the server setup where the web application and other required services are running on a single server and the database running on another server.
This layout helps us to scale independently both the web servers and database servers as per the volume of traffic and growth of the database.
Let's revise some points about the databases
There are broadly two types of databases available which are relational databases and non-relational databases.
Relational databases are a type of database management system (DBMS) that organizes and stores data in a tabular form, using tables, rows, and columns. The data in a relational database is structured and follows a predefined schema, which defines the tables, their columns, and the relationships between them.
Key features and concepts of relational databases include:
Tables: Data is stored in tables, which are organized into rows (also known as records or tuples) and columns (also known as attributes). Each table represents a specific entity or concept.
Primary Key: Each table typically has a primary key, which is a unique identifier for each row in the table. It ensures data integrity and facilitates efficient data retrieval.
Foreign Key: Relationships between tables are established using foreign keys. A foreign key in one table references the primary key of another table, creating a link between them.
Normalization: Relational databases use normalization techniques to eliminate data redundancy and improve data integrity. Normalization involves breaking down tables into smaller, more manageable entities and ensuring that each piece of data is stored in only one place.
SQL: Structured Query Language (SQL) is the standard language for interacting with relational databases. It provides a set of commands for creating, modifying, and querying the database structure and data.
ACID Properties: Relational databases typically adhere to ACID (Atomicity, Consistency, Isolation, Durability) properties to ensure data reliability and consistency in transactions.
Scalability: Relational databases can handle large amounts of data and support high concurrency. They offer scalability options like sharding, replication, and clustering to distribute data across multiple servers and handle increased workloads.
Examples: Popular relational database management systems include MySQL, Oracle Database, Microsoft SQL Server, PostgreSQL, and SQLite.
Relational databases are widely used for a variety of applications, from small-scale projects to large enterprise systems. They provide a structured and reliable way to store and manage data, making them suitable for applications that require data integrity, complex querying, and robust transactional support.
Non-relational databases, also known as NoSQL (Not Only SQL) databases, are a type of database management system that provides flexible and scalable storage solutions for unstructured, semi-structured, or rapidly changing data. Unlike relational databases, non-relational databases do not adhere to a fixed schema and typically use a variety of data models for storing and retrieving data.
Key features and concepts of non-relational databases include:
Flexible Schema: Non-relational databases allow for dynamic and flexible schemas, enabling data to be stored without predefined structure or constraints. This allows for easier handling of diverse and evolving data formats.
Data Models: Non-relational databases support various data models, such as key-value pairs, document-oriented, columnar, and graph-based. Each model offers specific advantages based on the nature of the data and the requirements of the application.
Horizontal Scalability: Non-relational databases are designed to scale horizontally, allowing for the distribution of data across multiple servers or clusters. This provides the ability to handle large amounts of data and high traffic loads with ease.
High Performance: Non-relational databases are optimized for high-speed data retrieval and processing. They employ techniques such as in-memory caching, parallel processing, and data partitioning to enhance performance.
No Joins: Unlike relational databases, non-relational databases typically do not support joins between multiple tables. Instead, denormalization techniques are used to store related data together, reducing the need for complex queries.
Eventual Consistency: Non-relational databases often prioritize availability and partition tolerance over strong consistency. They employ strategies like eventual consistency, where data consistency is achieved over time, allowing for improved performance and scalability.
Examples: Some popular non-relational databases include MongoDB (document-oriented), Apache Cassandra (wide-column), Redis (key-value), and Neo4j (graph-based).
Non-relational databases are commonly used in scenarios where the flexibility of the data model, horizontal scalability, and high-performance data processing are crucial. They are well-suited for applications that handle large volumes of unstructured or rapidly changing data, such as real-time analytics, content management systems, social networks, and Internet of Things (IoT) platforms.
Summarizing Up
Overall, system design is a critical phase that bridges the gap between requirements and implementation. It lays the foundation for successful software development by providing a well-structured, efficient, and scalable system that meets the desired objectives of the project.
Relational databases, characterized by structured tables and SQL queries, provide a reliable and consistent way to store and manage data with defined schemas. They excel in maintaining data integrity and handling complex relationships. Non-relational databases, on the other hand, offer flexible schemas, scalability, and high-performance capabilities, making them suitable for unstructured and rapidly evolving data. NoSQL databases utilize various data models and prioritize horizontal scalability. Choosing between relational and non-relational databases depends on the specific requirements of an application, considering factors such as data structure, scalability needs, and performance demands. Both types have their place in the landscape of database management systems.