




System design refers to the process of conceptualizing and structuring a software system to address specific requirements. It involves identifying the system's components, their relationships, and interactions, and designing their interfaces. System design encompasses architectural decisions, data flow, communication protocols, algorithms, and storage considerations. The goal is to create a robust, scalable, and efficient system that meets functional and non-functional requirements such as performance, reliability, and security. It requires knowledge of software engineering principles, design patterns, and trade-offs. System design is crucial in building complex software applications that effectively solve real-world problems.
Understanding Database Replication
Database replication is the process of creating and maintaining multiple copies of a database to ensure data availability, fault tolerance, and scalability. It involves copying data from one database (known as the "source" or "master" database) to one or more target databases (known as "replicas" or "slaves") in real-time or near-real-time.
The primary goal of database replication is to provide redundancy and improve system performance by distributing the workload across multiple database servers. It also ensures data integrity and provides fault tolerance in case of hardware failures, network outages, or other disasters.
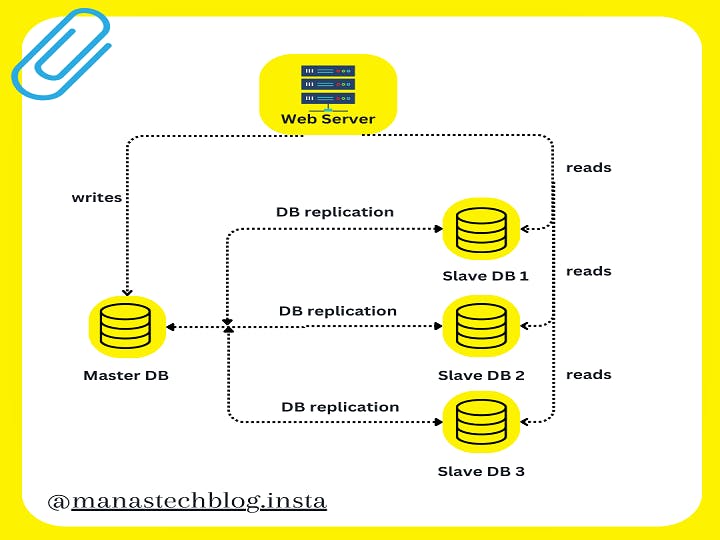
Here's a detailed explanation of the key components and concepts involved in database replication:
Source Database: The source database is the primary database that contains the original and authoritative data. Any updates, inserts, or deletes performed on this database are captured and propagated to the replicas.
Replica Databases: Replica databases are copies of the source database. They receive data changes from the source and apply them to maintain consistency with the source. Replica databases can be located on separate servers or distributed across different geographical locations.
Replication Process: The replication process consists of three main steps:
a. Data Capture: Changes made to the source database are captured and recorded in a format suitable for replication. This can be achieved using various techniques such as transaction logs, trigger-based capturing, or change data capture (CDC) mechanisms.
b. Data Transmission: Captured data changes are transmitted from the source database to the replicas. The data transmission can be synchronous (immediately applied to replicas) or asynchronous (replicas apply changes at a later time).
c. Data Application: Once the data changes are received by the replicas, they are applied to the replica databases to keep them synchronized with the source. This typically involves executing the captured changes in the same order they occurred on the source database.
Replication Modes: There are different replication modes, each offering specific characteristics and trade-offs:
a. Master-Slave Replication: In this mode, the source database acts as the master, and one or more replicas act as slaves. The master receives all write operations, and the changes are then propagated to the slaves. Read operations can be distributed among the slaves to offload the master and improve read scalability.
b. Master-Master Replication: In this mode, there are multiple master databases, and each can accept both read and write operations. Changes made on one master are replicated to the other masters, ensuring data consistency across all nodes. Master-master replication provides high availability and load balancing for read and write operations.
c. Multi-level Replication: This mode involves cascading replication, where replicas act as sources for additional replicas. Changes are propagated through multiple levels of replication, enabling scalability and fault tolerance.
Replication Topologies: Replication topologies define the structure and relationships between the source and replica databases. Some common topologies include:
a. Master-Slave Topology: In this topology, a single master replicates data to multiple slaves.
b. Master-Master Topology: Multiple masters are interconnected, and data changes are replicated bidirectionally.
c. Fan-out Topology: Data changes from a single source database are replicated to multiple replicas, forming a fan-out pattern.
d. Ring Topology: Each replica acts as both a source and a destination, forming a circular chain of replication.
Consistency Models: Database replication systems employ different consistency models to ensure data consistency across replicas. Some common models include:
a. Strong Consistency: All replicas have an up-to-date and consistent view of the data at all times. Changes are applied synchronously across replicas.
b. Eventual Consistency: Replicas eventually become consistent but may have temporary inconsistencies during replication. Changes are applied asynchronously, and conflicts are resolved using conflict resolution mechanisms.
c. Read Consistency: The consistency model guarantees that read operations always return the most recent committed data but does not guarantee consistency for write operations.
Database replication plays a crucial role in distributed systems, high availability architectures, disaster recovery setups, and scaling read and write workloads. The specific implementation and configuration of replication depend on the database management system (e.g., MySQL, PostgreSQL, Oracle) and the requirements of the application or system using the databases.
Understanding Database Replication Layout
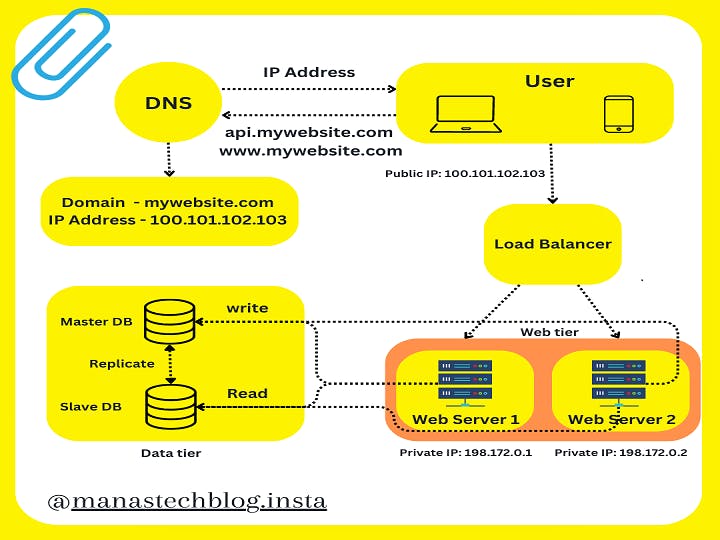
Let's understand the flow of information
A user requests mywebsite.com and the DNS server returns Public IP 100.101.102.103
This Public IP is the address of the load balancer.
Then load balancer routes the traffic either to Web Server 1 or Web Server 2.
The web server will read the data from the slave database.
The web server will write, update and delete the data to the master database.
And finally, the master database will replicate all the changes in the slave database.
Advantages Of Database Replication
Let's see some advantages of database replication.
High Availability: Database replication ensures that multiple copies of the data are available. If the primary database (source) experiences a failure or becomes inaccessible, one of the replica databases can take over and continue serving requests, ensuring uninterrupted access to data.
Fault Tolerance: Replication provides fault tolerance by distributing data across multiple servers. In the event of a hardware failure, network outage, or natural disaster affecting one server, the replicas can continue to serve data, preventing data loss and minimizing downtime.
Improved Performance and Scalability: Replication enables load balancing by distributing read operations across replica databases. This offloads the primary database from read-intensive workloads, improving overall system performance and scalability.
Localized Data Access: Replicas can be located in different geographical regions, allowing data to be accessed locally by users or applications. This reduces latency and improves response times, particularly in distributed or globally dispersed environments.
Disaster Recovery: Replication provides a mechanism for disaster recovery by maintaining up-to-date copies of the data in separate locations. In the event of a catastrophic failure or data loss, replica databases can be promoted to the primary role, ensuring business continuity and minimizing data recovery time.
Scalable Write Workloads: In some replication modes, such as master-master replication, write operations can be distributed across multiple databases. This enables scaling of write-intensive workloads by allowing concurrent writes on different nodes, increasing the system's capacity.
Data Distribution and Consolidation: Replication can be used to distribute data across multiple databases, enabling data consolidation or data partitioning strategies. This is particularly useful in scenarios where data needs to be localized or segmented based on specific criteria.
Offline Analysis and Reporting: Replica databases can be used for offline analysis, reporting, and backups without affecting the performance or availability of the primary database. This allows organizations to perform resource-intensive operations without impacting the production environment.
Zero-Downtime Maintenance: Replication facilitates performing maintenance tasks on the primary database without causing downtime. By redirecting traffic to replica databases, the primary database can be taken offline for maintenance, upgrades, or optimizations while still ensuring data availability.
Data Consistency and Integrity: Replication ensures data consistency across multiple databases by propagating changes from the source to the replicas. This helps maintain data integrity and avoids data discrepancies that can occur in distributed systems.
Summarizing Up
Database replication is the process of creating and maintaining multiple copies of a database, ensuring data availability, fault tolerance, and scalability. It involves capturing data changes from a source database and transmitting them to replica databases in real-time or near-real-time. Replication provides high availability by allowing replicas to take over if the primary database fails. It improves performance by distributing the workload across multiple servers and enables scalability for both read and write operations. Replication also facilitates disaster recovery, data distribution, and localized data access. It ensures data consistency, integrity, and supports offline analysis, while allowing for zero-downtime maintenance. Overall, database replication enhances data reliability and continuity in critical systems.