


06 - System Design - Basic Understanding - Architecture State And Data Centers


System design refers to the process of conceptualizing and structuring a software system to address specific requirements. It involves identifying the system's components, their relationships, and interactions, and designing their interfaces. System design encompasses architectural decisions, data flow, communication protocols, algorithms, and storage considerations. The goal is to create a robust, scalable, and efficient system that meets functional and non-functional requirements such as performance, reliability, and security. It requires knowledge of software engineering principles, design patterns, and trade-offs. System design is crucial in building complex software applications that effectively solve real-world problems.
Stateful architecture maintains user state across multiple requests, allowing for personalized experiences and efficient data storage. It remembers user information, preferences, and session data, enabling context-aware decision-making. In contrast, stateless architecture treats each request as independent, without retaining any user-specific data. It offers scalability, fault tolerance, and simplified server design by avoiding session management. However, it lacks personalization and context between requests, requiring all necessary information to be included in each request. Stateless architectures are suitable for highly distributed systems, while stateful architectures excel in scenarios requiring persistent user interactions and personalized experiences.
Understanding Stateful Architecture
In system design, stateful architecture refers to an approach where the system or application maintains and manages the state or data related to a user's interactions or transactions over multiple requests or sessions. It means that the system remembers and keeps track of the information specific to each user, such as their preferences, session data, shopping cart contents, or any other relevant data.
Stateful architecture is in contrast to stateless architecture, where each request from a client is handled independently, without any knowledge or memory of previous interactions. In a stateless architecture, all the necessary information to process a request is contained within that particular request, and the server does not retain any context or history about the user.
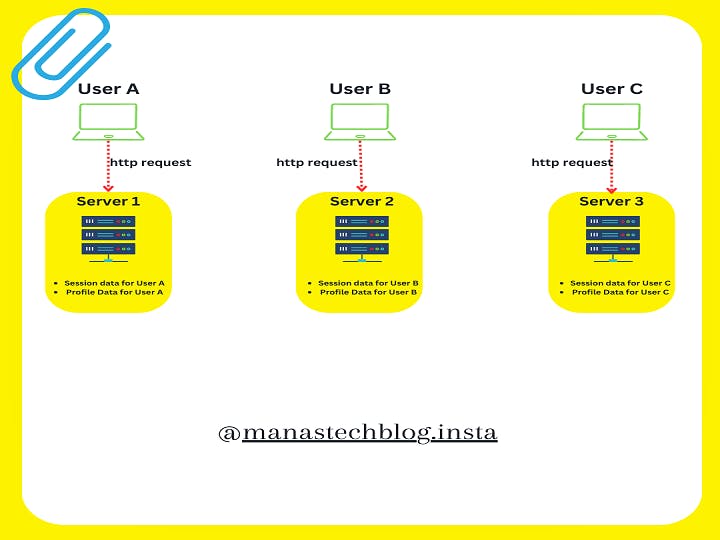
In a stateful architecture, the server stores and manages the user's state, typically in a database, cache, or session storage, and associates it with a unique identifier (such as a session ID or user ID). This allows the system to provide a personalized and continuous experience to the user, as it can recall their preferences and context from previous interactions. The server can retrieve the user's state when processing subsequent requests, enabling features like user authentication, maintaining shopping carts, and remembering user-specific settings.
Stateful Architecture Advantages
Stateful architectures can offer several advantages, including:
Personalization: By maintaining user state, the system can provide customized experiences tailored to individual users based on their history and preferences.
Efficiency: Storing user state can reduce redundant data transmission, as the server doesn't need to send the same information repeatedly in every request. This can improve performance and reduce network overhead.
Contextual decision-making: With access to historical data, the system can make informed decisions based on the user's previous actions and behavior.
However, stateful architectures also introduce challenges such as managing session state, scalability, and synchronization across multiple servers or instances. Care must be taken to ensure data consistency, handle concurrent access, and plan for potential failure scenarios.
Overall, stateful architectures are suitable for applications that require persistent user interactions and personalized experiences, but they require careful design and implementation to address the associated complexities and trade-offs.
Understanding Stateless Architecture
In system design, a stateless architecture refers to an approach where the system or application treats each request from a client as an independent, self-contained unit. It means that the server does not maintain any information or memory about the client's previous interactions or requests.
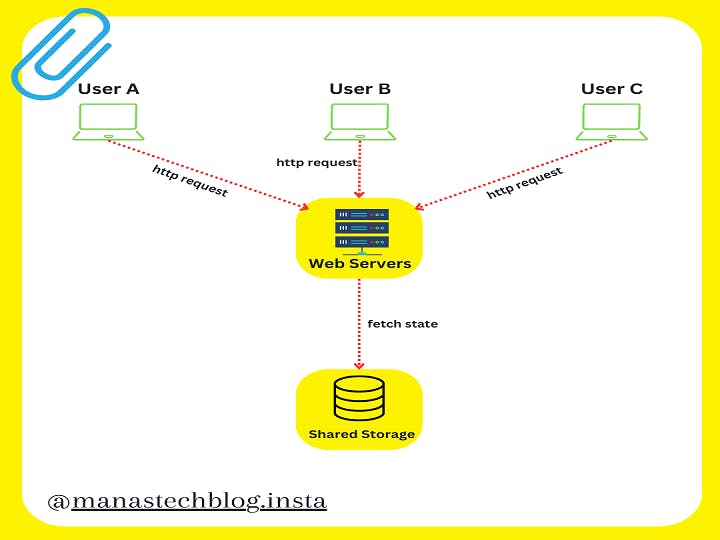
In a stateless architecture, every request contains all the necessary data and context for the server to process it. The server does not rely on any stored session information or user-specific data. Instead, it derives the required information solely from the request itself. This approach allows the server to handle each request in isolation and without any dependency on past interactions.
Stateless Architecture Advantages
Stateless architectures can offer several advantages, including:
Scalability: Since there is no need to store and manage session state, the system can easily scale horizontally by adding more servers. Each server can independently handle any incoming request, making it easier to distribute the workload.
Fault tolerance: Statelessness simplifies fault tolerance because requests can be processed by any available server without the need for session affinity. If one server fails, another server can take over the processing seamlessly.
Simplified server design: Servers in a stateless architecture are simpler as they don't need to maintain and manage session data. This simplicity often translates into improved performance and easier maintenance.
Caching and load balancing: Stateless architectures are conducive to caching and load balancing strategies. Since each request contains all the necessary information, responses can be cached at various levels (such as CDN or proxy servers) to improve performance. Load balancers can also distribute requests evenly across multiple servers without worrying about session affinity.
Stateless Architecture Limitations
Statelessness also has limitations:
Lack of context: Stateless architectures cannot maintain context or remember user-specific information between requests. Therefore, each request must include all the required data, which can increase the payload size and potentially affect network performance.
Redundant data transmission: Since each request must contain all the necessary information, there might be redundant data transmission, especially if certain data remains constant across multiple requests. This can result in increased network bandwidth consumption.
Limited personalization: Stateless architectures are not inherently suitable for scenarios that require personalized experiences or context-awareness. Each request is treated independently, and the system cannot recall user preferences or history without external means of storing and retrieving such data.
Stateless architectures are commonly used in web applications and APIs, where requests are typically isolated and self-contained. They offer simplicity, scalability, and fault tolerance, making them well-suited for highly distributed and scalable systems. However, the lack of context and user-specific state must be carefully considered when designing applications that require personalized experiences or session management.
Data Centers
In system design, data centers play a crucial role in providing a reliable and efficient infrastructure for storing, processing, and managing large volumes of data and applications. A data center is a centralized facility or a group of interconnected facilities that house computing and networking resources, including servers, storage systems, and networking equipment.
Data centers are designed to provide a secure and controlled environment to ensure the availability, integrity, and confidentiality of data. They typically feature redundant power supplies, backup generators, cooling systems, fire suppression mechanisms, physical security measures, and network connectivity to support uninterrupted operations.
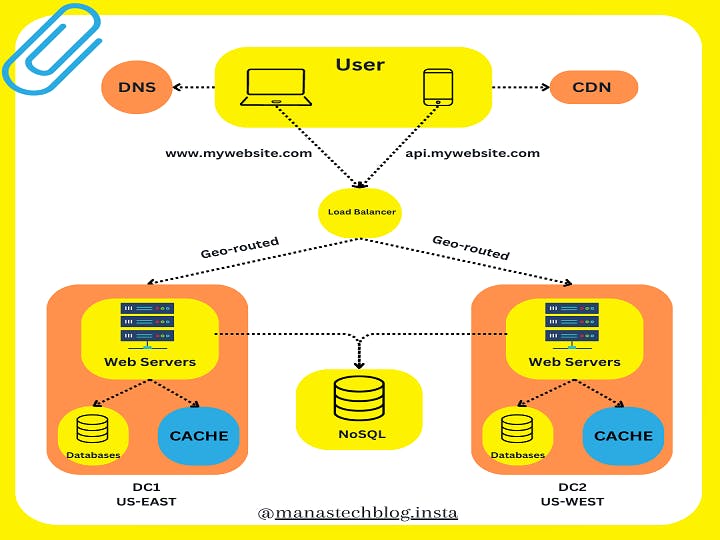
Let's consider an example setup of two data centers functioning as cloud regions, providing cloud services to users:
Data Center 1 (US-EAST): Located in a geographically distinct area, Data Center 1 serves as a primary cloud region. It consists of multiple server racks organized in rows. Each rack contains compute nodes, storage devices, and networking equipment. Power distribution units and cooling infrastructure ensure reliable operations. Network switches and firewalls connect the servers and provide external connectivity. Data Center 1 is designed for high availability, with redundant power supplies, backup generators, and replicated data storage.
Data Center 2 (US-WEST): Data Center 2 is geographically separated from Data Center 1 to ensure geographic redundancy and disaster recovery capabilities. It mirrors the setup of Data Center 1, featuring server racks, power distribution, cooling infrastructure, network infrastructure, and storage systems. Data Center 2 acts as a secondary or backup region, providing failover capabilities in case of any disruptions in Data Center 1. It maintains synchronized copies of data through replication mechanisms.
Both data centers are interconnected through dedicated high-speed network links to enable data replication and failover mechanisms. They operate as independent regions, allowing users to deploy and scale their applications and services across multiple regions for enhanced performance, fault tolerance, and disaster recovery.
By leveraging the setup of two data centers as cloud regions, users can benefit from geographical redundancy, reduced latency, and the ability to handle high loads while ensuring the availability and reliability of their applications and data.
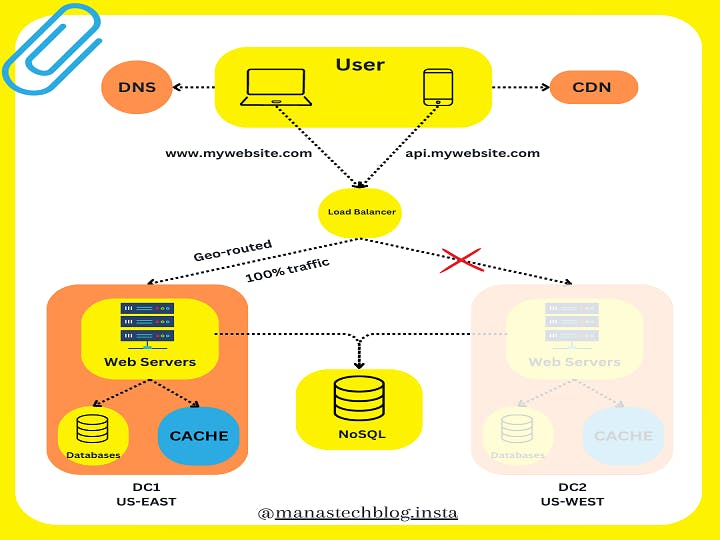
In the event of any significant data center outage, we direct all the traffic to a healthy data center. Data center 2 (US-WEST) is offline, and 100% of the traffic is routed to the data center.
Summarizing Up
In summary, data centers provide the infrastructure for storing and processing data, while stateless architecture treats requests independently without retaining user-specific data, and stateful architecture maintains and manages user state for personalized experiences and persistent interactions.