




System design refers to the process of conceptualizing and structuring a software system to address specific requirements. It involves identifying the system's components, their relationships, and interactions, and designing their interfaces. System design encompasses architectural decisions, data flow, communication protocols, algorithms, and storage considerations. The goal is to create a robust, scalable, and efficient system that meets functional and non-functional requirements such as performance, reliability, and security. It requires knowledge of software engineering principles, design patterns, and trade-offs. System design is crucial in building complex software applications that effectively solve real-world problems.
Database scaling refers to the process of adjusting the capacity and performance of a database system to accommodate increasing amounts of data, user traffic, or workload demands. Scaling is necessary to ensure optimal performance, high availability, and efficient utilization of resources as the database grows.
There are two primary types of database scaling:
Vertical Scaling (Scaling Up)
Vertical scaling involves increasing the capacity of a single database server by adding more resources such as CPU, memory, or storage to handle the increased workload. It typically involves upgrading hardware components or moving to a more powerful server. Vertical scaling is suitable for applications with low to moderate traffic or when the database workload can be handled by a single server.
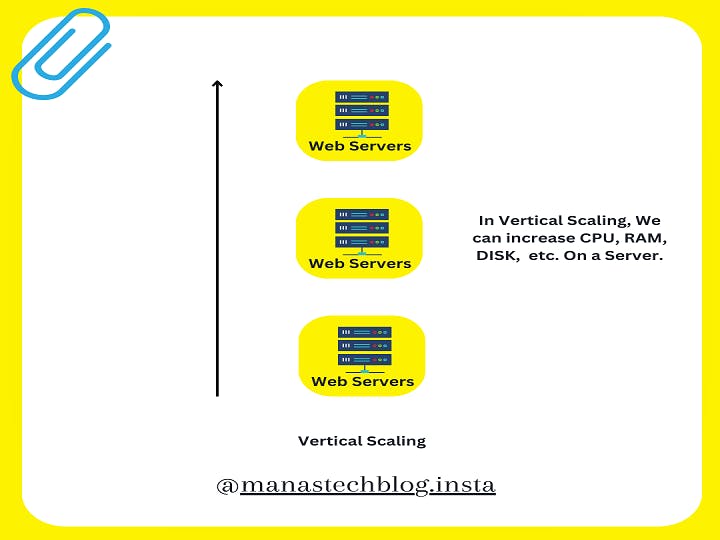
Pros of Vertical Scaling:
Simple and straightforward to implement.
Minimal changes are required to the application layer.
Can be cost-effective for small-scale requirements.
Cons of Vertical Scaling:
Limited scalability potential based on the capacity of a single server.
Possibility of hardware limitations or bottlenecks.
Downtime may be required during hardware upgrades.
Horizontal Scaling (Scaling Out)
Horizontal scaling involves distributing the database load across multiple servers or instances to handle increasing demands. It is achieved by adding more servers to the database cluster, which allows for higher throughput, improved fault tolerance, and better scalability. Horizontal scaling is suitable for applications with high traffic or rapidly growing datasets.
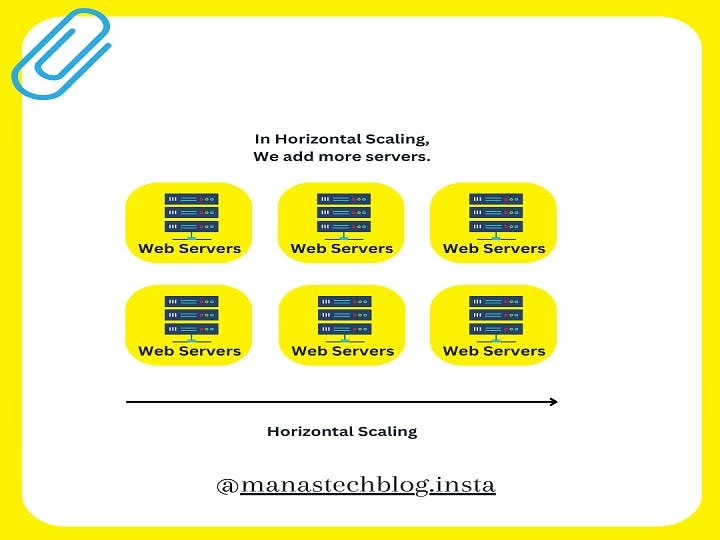
Pros of Horizontal Scaling:
Improved scalability as multiple servers can handle the workload.
Better fault tolerance and high availability through replication and data distribution.
Ability to add or remove servers as needed to match demand.
Cons of Horizontal Scaling:
Increased complexity in managing a distributed system.
Data consistency and synchronization challenges across multiple instances.
Application layer changes may be required to support distributed queries.
To implement horizontal scaling, there are two common approaches:
Database Sharding
Sharding involves partitioning the data across multiple servers based on a chosen sharding key. Each server handles a subset of the data, allowing for parallel processing and improved performance. Sharding can be done at the application level or within the database system itself.
Database sharding is a technique used in distributed database systems to horizontally partition data across multiple servers or shards. Each shard contains a subset of the data, allowing for parallel processing and improved scalability. Sharding is commonly employed to address the limitations of vertical scaling (scaling up) by distributing the database workload across multiple servers.
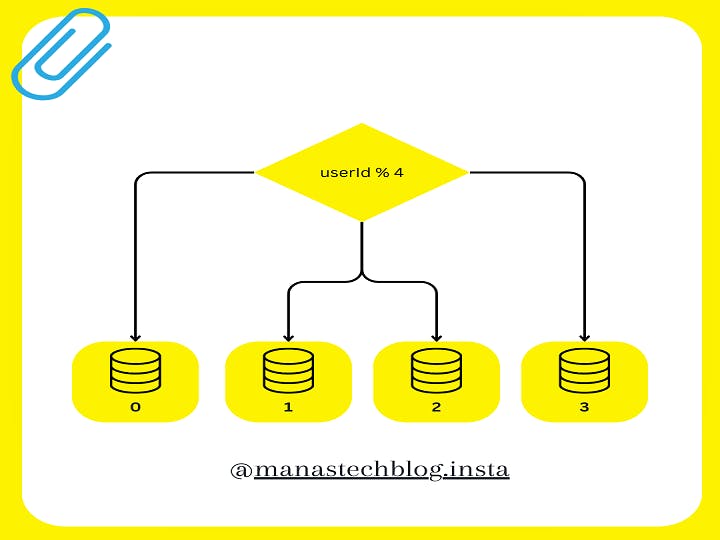
Here's a detailed explanation of how database sharding works:
Shard Key Selection: The first step in implementing database sharding is selecting an appropriate shard key. The shard key is a field or set of fields in the data that determines how the data is divided among shards. It should be chosen carefully to ensure an even distribution of data and avoid hotspots where a single shard becomes a performance bottleneck.
Data Partitioning: Once the shard key is selected, data is partitioned based on the shard key value. Each data record is assigned to a shard based on the shard key. The partitioning algorithm determines which shard will store a particular record by applying a hashing function or range-based logic to the shard key value. The goal is to evenly distribute the data across shards to achieve balanced workload distribution.
Shard Creation: Shards are individual database instances or servers that store a subset of the data. When setting up sharding, multiple database servers are provisioned to host the shards. Each shard operates as an independent database, managing its portion of the data.
Query Routing: To execute a query, the application or a routing layer needs to determine which shard or shards contain the relevant data for that query. This is done by analyzing the shard key in the query and mapping it to the corresponding shard or shards. The query is then routed to those shards to retrieve the required data.
Aggregation and Merging Results: In some cases, a query may span multiple shards if it involves data from different shards. The routing layer collects the results from each shard and aggregates them to provide a unified response to the application. The aggregation step may be handled by the routing layer or the application itself, depending on the specific implementation.
Data Consistency and Availability: Ensuring data consistency and availability across shards is crucial. Different approaches can be used to maintain consistency, such as two-phase commit protocols, distributed transactions, or eventual consistency models. Additionally, sharded databases often employ replication within each shard to provide fault tolerance and high availability.
Benefits of Database Sharding:
Improved Scalability: Sharding allows databases to handle increased data volume and user traffic by distributing the workload across multiple servers.
Enhanced Performance: Sharding enables parallel processing of queries, leading to improved response times and throughput.
Cost Optimization: By horizontally scaling the database, sharding can be more cost-effective than vertically scaling a single server.
Fault Tolerance: Sharding with data replication provides redundancy and fault tolerance, ensuring high availability even in the event of server failures.
Challenges of Database Sharding:
Data Distribution Complexity: Designing an effective sharding strategy requires careful consideration of the shard key, data distribution, and query routing mechanisms.
Data Consistency: Ensuring data consistency across shards can be challenging, especially in distributed systems where updates may span multiple shards.
Complex Queries: Queries that involve data from multiple shards may require additional coordination and aggregation steps to consolidate the results.
Database sharding is a powerful technique for scaling distributed database systems, enabling efficient storage, retrieval, and processing of large volumes of data. It requires careful planning, design, and ongoing maintenance to ensure optimal performance and data consistency across shards.
Database Replication
Replication involves creating copies (replicas) of the database across multiple servers. Each replica can serve read requests independently, providing scalability for read-heavy workloads. Replication can be synchronous or asynchronous, depending on the desired level of data consistency and performance requirements.
Database replication is the process of creating and maintaining one or more copies (replicas) of a database to ensure data redundancy, fault tolerance, and improved performance. Replication is commonly used in distributed database systems to enhance availability, facilitate disaster recovery, and distribute the database workload. Here's a detailed explanation of how database replication works:
Primary-Secondary Model: Database replication typically follows a primary-secondary model, where one database instance serves as the primary or master, and one or more instances act as secondary or replica servers. The primary server is responsible for handling read and write operations, while replica servers maintain copies of the primary database.
Replication Modes: There are different replication modes or approaches based on how data is synchronized between the primary and replica servers:
a. Synchronous Replication: In synchronous replication, each write operation is committed on the primary server and then immediately replicated to the replicas before the acknowledgment is sent back to the client. This ensures that the replicas are always up to date but can introduce latency in write operations due to the need for synchronous communication.
b. Asynchronous Replication: In asynchronous replication, the primary server acknowledges the write operation to the client before replicating the data to the replicas. This allows for faster write operations but introduces a slight delay in data synchronization between the primary and replicas.
The choice between synchronous and asynchronous replication depends on the desired level of data consistency and performance requirements of the application.
Replication Process: The replication process involves the following steps:
a. Initial Snapshot: Initially, a full copy or snapshot of the primary database is created and transferred to the replica servers. This establishes the initial state of the replicas.
b. Log-based Replication: After the initial snapshot, changes made to the primary database are captured in the form of database logs or transaction logs. These logs contain the sequence of operations (inserts, updates, deletes) performed on the primary database.
c. Log Shipping: The logs from the primary server are shipped or transmitted to the replica servers. The replica servers apply these logs in the same sequence to maintain an identical copy of the primary database.
d. Apply and Replay: The replica servers apply the received logs to their local copies of the database, replaying the same operations that were performed on the primary server. This brings the replica servers up to date with the primary database.
Read Operations: Replica servers can handle read operations independently, as they have an up-to-date copy of the primary database. This allows for load balancing and improved read performance by distributing read queries across multiple replica servers.
High Availability and Failover: Replication provides fault tolerance and high availability. If the primary server becomes unavailable due to a failure or maintenance, one of the replica servers can be promoted to the role of the new primary server. This process, known as failover, ensures that the database remains accessible even in the event of a primary server failure.
Benefits of Database Replication:
Increased Availability: Replication provides redundancy and failover capabilities, minimizing downtime and ensuring continuous access to the database.
Improved Read Performance: Replica servers can handle read operations, distributing the workload and improving response times for read-heavy workloads.
Disaster Recovery: Replicas serve as a backup in case of data center failures, natural disasters, or other catastrophic events.
Scalability: Replication allows for scaling read capacity by adding more replica servers to handle increased read traffic.
Challenges of Database Replication:
Data Consistency: Ensuring consistency across replicas can be complex, especially in asynchronous replication where there can be a slight delay in data synchronization.
Network Overhead: Replication requires sufficient network bandwidth to transmit the logs or changes from the primary server to the replicas.
Configuration and Monitoring: Proper configuration and monitoring of the replication process are necessary to maintain consistency and performance.
Database replication is a powerful mechanism to enhance data availability, performance, and reliability in distributed database systems. It requires careful planning, configuration, and ongoing monitoring to ensure proper replication and synchronization of data between the primary and replica servers.
Summarizing Up
Database scaling involves adjusting the capacity and performance of a database system to accommodate growing data, user traffic, and workload demands. It can be achieved through vertical scaling (increasing server resources) or horizontal scaling (distributing data across multiple servers). Vertical scaling improves the capacity of a single server, while horizontal scaling enables parallel processing and fault tolerance. Sharding partitions data across shards, allowing for scalability and distributed processing. Replication creates replicas of the database to enhance availability and performance. Scaling involves considerations such as data consistency, load balancing, failover, and monitoring. Effective database scaling ensures optimal performance and high availability as the system expands.